By Scott Mauvais
Over the
last two months, I have written about applying the Microsoft
Solutions Framework (MSF) to creating fast, available, and scalable
(FAS) Web sites. In the first article, I analyzed the envisioning phase
and in the second, I moved on to the planning phase. If you're new to MSF,
that's okay. You can think of it as an interrelated series of concepts,
models, and best practices that lay the foundation for planning, building,
and managing technology projects. For a great hands-on development book
that walks you through a project's life cycle using MSF, see Microsoft� Mastering:
Enterprise Development Using Microsoft Visual Basic� 6.0.
This
month we conclude our look at creating high performance web sites with a
look at the developing phase. In this phase, the goal is to translate the
functional specification into running code. In this article, we focus on
two key areas:
� Optimizing techniques that improve the speed
and scalability of your web site
� Using stress-testing tools
to verify the performance of your site
During the planning phase, I
suggested that you should focus ruthlessly on the availability of your
site. The developing phase is all about being fast.
Optimization
Being fast is all about
optimizing your code. The applications running on most data-driven web
sites spend the majority of their time accessing data from the backend
database and relatively little time actually rendering the HTML to send to
the browser. Because you always want to focus your optimization efforts on
areas where you can have the biggest impact, it makes sense to start off
with data access.
Data
access
Probably the single most important thing you can do to
ensure the good performance of your web site is to choose the appropriate
means of accessing your database. When building your application on the
Microsoft platform, your choices fall into four broad categories: Static
HTML, IDC, SQLXML, and ASP. Because each of these approaches offers a
different development model, choosing the correct one for your application
will have a dramatic affect on the performance of your application. Before
describing the trade-offs you need to make when deciding which to use,
I'll give you a quick review of each
technology.
� Static HTML. Using
this approach, IIS simply serves up pages from the file system rather than
having to connect to the database or execute some code to calculate
results. To create these pages, you can use SQL Server's Web Assistant to
build static Web pages based on the data in your database. To do this, you
give the Web Assistant the name of a table, a query, or a stored procedure
you want to use as a source for the page and then you provide a template
HTML file to use to format the pages. The best part is that you can
configure SQL Server to update these pages regularly (say, every hour) or
every time the data changes.
� Internet Data
Connector. This technology, often referred to as simply IDC,
originally shipped as part of IIS 2.0 and is a simple way to retrieve
list-style data from your database. Using this approach, you create an IDC
file that defines the query you want to execute (ODBC source, username,
password, or SQL String) and an HTX template file to format the results
This differs from the static HTML approach because IIS queries the
database each time the user hits the IDC file rather than just the one
time when the Web Assistant creates the pages.
� SQL
XML. To query the database and send XML back to the browser, you
can use the new XML integration technology for SQL Server. The great thing
about this approach is that you can send an XML result set to the browser
without having to do any custom programming. You can also include an XSL
(Extensible Stylesheet Language, formerly called Extensible Style
Language) style sheet so that the browser formats the page and reduces the
load on the server.
� ASP. In cases where you
need more programmatic control, ASP is your best bet. With it, you can use
ADO to connect to your back-end data store and send data to the browser.
Because it supports COM and any ActiveScript language (that is, VBScript,
JScript, PerlScript, and so on), you can use ASP to perform most any sort
of programming task you need.
To determine the relative performance
of each of these methods, I first created a Web application
that displays the total sales for each customer in the sample Northwind
database using each of the four approaches. Next I used Microsoft's Web Application Stress Tool to
simulate several dozen users hitting each of the pages individually until
the CPU on my Web server reached 100 percent. Finally I used the
Transaction Cost Analysis methodology to calculate the CPU cost per page
for each of the approaches. (Note: If you are new to building dynamic Web
applications and want some additional information on these technologies,
you should check out Jim Buyens' book from Microsoft Press, Web Database
Development Step by Step.)
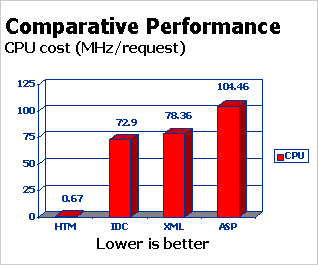
Figure 1: Comparative Performance CPU
Cost
The graph in Figure 1 shows the results of this analysis.
Before examining the results, I want to make an important point about the
specific numbers: your mileage may (and probably will) vary. The specific
numbers themselves really have no meaning, because they are specific to
the environment in which I did the testing. Rather, we are interested in
the relative differences among the methods. In other words, it is not
interesting at all that the static HTML approach cost less than one MHz
per request while the ASP method came in at over 104. What is extremely
interesting, however, is that static HTML is about 150 times cheaper than
ASP.
So we're interested in this graph because it tells us that we
should use static HTML if at all possible. If you look over your site, you
find that many of the pages don't change very often. For most e-commerce
sites, the product catalog as a whole is fairly static and product detail
pages themselves change very rarely. In such cases, you see a huge
performance increase if you move these pages to static HTML rather than
leaving them in ASP where you have to load the scripting engine, parse the
code, execute script, and hit the database for each request only to return
the same HTML back to the browser every time.
Say you have 50,000
items in your product catalog; how will you create these static HTML
pages? Surely I'm not suggesting that you manually create each page. Of
course not. This is a situation in which you can use SQL Server's Web
Assistant. All you need to do is give it a template HTML file and a query
that returns all the information for your product detail pages; the Web
Assistant will merge the two and generate a page for each inventory
item.
That takes care of the pages that remain unchanged for long
periods of time, but what about pages that are truly dynamic? If your
application has several standard, report-style queries, the IDC model will
give the best results but its flexibility is somewhat limited. In cases in
which you need more control over formatting or you're planning to build an
integration layer between different applications (or even different
companies), SQL XML is your best choice.
In some cases, however,
you need a full development environment like ASP to meet the application's
requirements. In these cases, you should consider caching the data if
possible. You'll still have the overhead of loading, parsing, and
executing the script, but you'll save the time required to process the
database calls, which is often upwards of 60 percent of the time spent in
ASP code.
Caching Data
You must
think carefully about how to approach the problem of caching. Caching
falls under the traditional size versus performance rule common in most
software applications. The rule states that if you increase the footprint
of your application, you can increase its performance but only up to a
point. As you continue to increase the size, you start to get smaller and
smaller marginal improvements in performance. In many cases, as you
approach the asymptote, the performance curve bends backward because the
size of the application starts to harm performance.
Caching suffers
from a backward-bending curve. If you allocate too little memory to cache,
you diminish performance because you spend too much time continuously
refetching the same data. On the other hand, if you allocate too much, you
also hurt performance of your Web site because you starve the operating
system of enough memory to operate efficiently. Worse still, either your
cached data becomes stale or you spend more CPU time keeping it current
than you actually save by not having to go out to disk to retrieve the
data.
Unfortunately, there is no simple formula to tell you how
much memory you should set aside for the cache. Picking the proper amount
is often a tedious, trial-and-error exercise, but the process is well
documented and there are many tools available. For a comprehensive
treatment of the issues involved and to learn more about analyzing the
memory needs of your application, see the Microsoft� Windows�
2000 Server Resource Kit.
After you determine how much memory
you want to set aside for caching, you still need to decide what data you
want to cache and where and how you want to store it. Deciding on what
data to store is highly dependant on your specific application but should
be pretty straightforward because you're probably familiar with your
applications data access patterns. As a starting point, I usually look at
combo boxes and lookup values first because they rarely change and are
accessed by many users.
As an example, let's assume you're
developing the checkout portion for a standard B2C Web site. As part of
the process, you need to let shoppers select their shipping methods.
You're a good developer, so rather than hard code the names of your
current shipping vendors in the HTML, you decide to make a call out to the
company's ERP system to retrieve their current list of shippers. That way,
when your customer adds new shipping partners, they won't have to change
the application. The downside of this approach is that it requires an
expensive database call for each user checking out.
As an
alternative, you could use the intrinsic Application object of IIS to
store a copy of this data. Once you populate it, retrieving data from the
Application object is often as much as 60 percent faster than accessing
from a database.
Now that you know what you want to store and
where you want to store it, you still need to decide how. Determining the
best way to store your cached data depends on how you plan to use it. Your
options fall into two broad categories: input caching or output caching.
When it comes to Web Applications input, caching refers to storing the
input from the data tier�the ERP system in our example. If you choose
output caching, you store the output sent back to the browser as HTML
snippets or XML.
If you always display data to the user in the
same format�you present a combo box from which to select shipping methods,
for example�you can use output caching to store the HTML fragment that
generates the combo box. If you need to display the data to users in more
than one format, you should use input caching and store the data in either
an array or a dictionary object. When it comes time to render the actual
HTML, you retrieve your array or dictionary from the cache and step
through it to create the HTML just as you would have stepped through the
ADO recordset returned from the ERP system�just must
faster.
Personally, I find output cache much easier to use, so I
tend to use that approach whenever possible. For cases in which I need to
display data in just two or three formats, I still use output caching and
simply use different variable names to cache the HTML used to render the
various formats. Sure, I'm not making the optimal use of memory, but I am
optimizing my development time, which I think is a good trade-off in most
cases.
If your data structures are so large that it does become
impractical to cache the same data in multiple formats, be sure to read
the Microsoft Product Support Services article HOWTO:
Declaring an Array at Application Level Scope because storing arrays
in the Application object can be a bit tricky.
One topic I haven't
addressed is how to refresh the cache when the source data changes. You
can choose from many different methods to accomplish this task (although a
description of them is outside the scope of this article). Microsoft has a
range of technical publications�books and articles� to help you. To get a
flavor for a couple of the options available as well as many more ideas to
help you optimize your web sites, see Len Cardinal and George Reilly's
excellent MSDN article about ASP tuning, 25+ ASP
Tips to Improve Performance and Style. For a lengthy discussion of the
registry settings you can tweak, see Todd Wanke's tuning white paper
entitled, Navigating the
Maze of Settings for Web Server Performance Optimization. If you're
doing a lot of database work, you must read (and re-read on a regular
basis) Improving
MDAC Application Performance by Suresh Kannan. Finally, for a
great source of information for developing high performance DNA
applications, you should get a copy of Designing for
Scalability with Microsoft Windows DNA by Sten and Per Sundblad,
published by Microsoft Press.
Stateless
Development
If you have read the two previous
articles in this series, you probably have a good feel for the
importance of stateless development from a high-level perspective.
Therefore, I won't cover too much detail here, but I do want to cover some
of the specifics as they relate to the development phase.
If you
rigorously follow the stateless model, your components won't maintain any
state information even between method calls. This means that you have to
reset all of your properties before each method call. Initially, you might
think this approach causes a net decrease in performance because of
bandwidth issues alone. You are, after all, sending the same setup
information and property data across the wire for every single method
call. As it turns out, the real hit in terms of network performance for
distributed applications is the cost of establishing the connection in the
first place; the cost of a few extra bytes (even several extra bytes) is
negligible. This makes sense because your state information probably fits
in the network frame as the rest of the call, so it won't take any longer
to transfer the data. Besides, even if you end up sending an extra frame
or two, it's not the end of the world because the cost of that extra data
is so small. To verify this for yourself, use Network Monitor to analyze
the packets sent between your Web Server and the components on a remote
application server for stateful and stateless calls.
While the
stateless approach is certainly the most scalable, it isn't always
practical and is usually quite burdensome for developers. A good middle
ground between stateful, client/service style programming and the
completely stateless approach is to ensure that your application doesn't
maintain any state information between pages. While this compromise
doesn't give you quite the same level of theoretical scalability as truly
stateless development, it's far easier for developers. Besides, I've never
seen a real World Wide Web application in which removing state between
method calls had a material impact.
After you have removed state
between pages, you want to examine how you're setting your component's
properties. Rather than set each of the properties separately, you want to
set them all in one function call. For example, you do not want to do
something like this:
Set oCustomer =
Server.CreateObject("ERP.CCustomer")
oCustomer.FirstName =
"Scott"
oCustomer.LastName = "Mauvais"
oCustomer.Address = "123 Main
street"
oCustomer.City = "Anytown"
oCustomer.Region
"CA"
oCustomer.PostalCode = "94000"
oCustomer.Add
The problem with this approach is that each �dot� represents a round
trip between the client application and the component. While this approach
is tolerable for in-process applications, it causes a significant
performance hit when you work with out-of-process components because each
time you set a property you force a cross-process call. For distributed
applications, this approach forces network connection. If you're dealing
with large distances, you begin to realize that the speed of light isn't
that fast after all; packets between San Francisco and New York average
about 70 ms of latency even on the fastest networks.
You can
optimize the preceding code by rewriting it like this:
Set
oCustomer = Server.CreateObject("ERP.CCustomer")
oCustomer. Add
("Scott", "Mauvais", "123 Main St.", "Anytown", "CA", "94000")
Here you have replaced seven calls into your component with a single
one.
For a comprehensive look at developing distributed
applications, you should take a look at Ted Pattison's newly revised
bestseller, Programming Distributed
Applications with COM+ and Microsoft� Visual Basic� 6.0, Second
Edition. Besides all the VB and COM information that made the first
edition an essential resource, this new version contains lots of real
world information on developing Web applications for Windows 2000 and
COM+. If you prefer a book that is more C++ focused, you can't go wrong
with Inside
Server-Based Applications by Douglas J. Reilly
Performance Testing
Many developers skip a
key part of the tuning process: testing the changes to verify they are
really faster than the previous version. I can't tell you how many times I
have tweaked some code that was obviously in need of some performance
tuning only to find it slower after I tuned it. The most recent example
involved a quick test when I changed some data access components to use
disconnected recordsets. In earlier projects, this technique had improved
overall performance because of reduced load on the server. In this
particular case, however, it was slower because of the size of the result
sets and the unique way in which users manipulated them.
Yes, it
was somewhat embarrassing having to sheepishly tell the customer that my
optimization strategy actually resulted in lower performance. Not nearly
as embarrassing, however, as it would have been had I urged the client to
migrate their entire site over to the use of disconnected recordsets only
to find out later about the effect of their unique uses of recordsets.
Now, the point of this isn't to discourage you from using disconnected
recordsets, rather, it is to illustrate the point about always verifying
that your optimizations really do lead to better performance.
A
related mistake programmers often make is they don't use realistic
scenarios to test their changes. Before you begin developing your test
scripts, it's very important that you understand the behavior of your
users as they navigate through your site. Assuming you're working to
optimize an existing site, the best source of this information is your Web
server's log files.
When you examine these logs, you want to look
for ways to simulate four types of load conditions:
� Average
concurrent. This condition represents the average number of users
accessing your site, all performing typical actions.
� Stress.
Stress load indicates the maximum number of concurrent users your site can
handle over an extended period of time.
� Peak. Peak load
differs from a stress load in that it assumes that many users are
performing a single task. An example of this would be month-end processing
during which not only do you have more users than usual, but also they're
all performing a fixed number of tasks, making the load
uneven.
� Event. An event load simulates activities tied to a
single, one-time event. The classic example is a Super Bowl ad.
You
need to develop test plans for each of these scenarios because each places
a different load on the server and therefore causes different components
to serve as the bottleneck. For example, under stress load you may find
that you are CPU bound, while under peak load your users might be blocked
by a single poorly written component. Network bandwidth is the limiting
factor in the event scenarios. To learn more about developing test plans
for your Web applications, see the Site
Server 3.0 Commerce Edition Resource Kit, which has some excellent
white papers on capacity planning and performance
monitoring.
Several tools are available to generate the actual load
on the server. Some of my favorites are these:
� InetMon from
the Microsoft�
BackOffice� Resource Kit Part Two
� WCAT from the Microsoft� Internet
Information Server Resource Kit
� Web Application Stress Tool,
which used to be called Homer
After you have used one or more of
these tools to generate various types of loads on your server, you need to
monitor your performance so that you know how to prepare for each of these
load conditions. You can use the tools that ship with Windows and SQL
Server such as Performance Monitor and SQL Profiler to help you. As long
as you're prepared for these various conditions, you'll surely identify
the bottlenecks; you won't resort to just throwing more hardware at the
problem and hoping it goes away.
Microsoft
Press Solutions
In this article, I conclude my discussion of
creating fast, available, and scalable web sites. I started off in the
first article looking at the envisioning process and some of the unique
challenges that Web developers face. Last month, I looked at the planning
phase where scalability took precedence. In this final article, I covered
some approaches to improve the performance of your components, such as
caching your data and insuring you are using the proper data access
technique. I also covered the importance of testing changes to ensure that
they really do improve performance.
Regardless of how long you have
been in the IT industry, Microsoft Press� provides several books that can
help advance your career and improve your technical skills. I mentioned
several titles in the article, so rather than force you to scroll back
though the article and look for the links, I have grouped them below by
topic.
Development
Web Database
Development Step by Step
Designing for
Scalability with Microsoft Windows DNA
Programming Distributed
Applications with COM+ and
Microsoft� Visual Basic� 6.0, Second
Edition
Microsoft� Mastering:
Enterprise Development Using
Microsoft Visual Basic� 6.0
Inside
Server-Based Applications
Resource Kits
Microsoft� Windows�
2000 Server Resource Kit
Microsoft� BackOffice�
Resource Kit Part Two
Microsoft� Internet
Information Server Resource Kit

