|
All Products | Support | Search | microsoft.com Home | ||
| Home | Register Books | Newsletter | Site Index | Book Lists | | |||
|
All Products | Support | Search | microsoft.com Home | ||
| Home | Register Books | Newsletter | Site Index | Book Lists | | |||
|
|
|||||||||
 SQL Server
2000: .NET and the Death and Re-Birth of Triggers By Scott Mauvais It seems everywhere you turn these days, everyone is talking about Microsoft's .NET initiative. Microsoft is certainly talking about it. The trade rags are taking about it. Every developer journal has articles about it. Last time I counted, there were just over independent 100 web sites devoted to it. Everyone is saying how great it will be. Surprisingly, no one seems to be focusing on the fact that first part of the .NET platform has already shipped. On September 26, SQL Server 2000 became the first .NET Enterprise Server. In this month's article I will cover an aspect of SQL Server that always generates a great deal of, well, shall we say "discussion"�triggers. Love them or hate them, SQL Server 2000 will change they way you think about triggers and will probably alter the way you design your applications. Specifically, this month I will dive into cascading referential integrity (RI) and the new INSTEAD OF and AFTER trigger concepts in SQL Server 2000. To round out your understanding of this, the first .NET Enterprise Server, you should also take a look at Ian Matthews' companion article in the IT Professional section on Microsoft Press Online, SQL Server 2000 New Features and Enhancements, that covers the features important to the IT professional such as SQL Server 2000's new XML features, support for greater multiprocessing, ability to run multiple instances on one server machine, and new administrative tools. Both of these articles focus exclusively on using the new features of SQL Server 2000. If you are looking for a comprehensive look at the inner working of SQL Server 2000, you need to get a copy of Ron Soukup's and Kalen Delaney's Inside Microsoft SQL Server 2000 from Microsoft Press. They just finished revising their best selling, Inside Microsoft SQL Server 7.0 to provide essential insight into the architectural changes in SQL Server 2000. I just finished reading an early version of it and I must say, it is truly outstanding. Even if you have the 7.0 edition (or Ron's 6.5 version) you should purchase a copy of the new release as soon as you can because it tells you why SQL Server 2000 is the way it is and shows you how to use it to its full potential. Now that you know where you can find additional
information on SQL Server 2000, let's get back to triggers. Before we dive
into the detail, I need to come clean. In the spirit of full disclosure,
you should know I hate triggers; I always have. They are tedious to write,
difficult to debug, and when it comes right down to it, most developers
only use them for cascading referential integrity. I have always been a
bit annoyed that SQL Server didn't take care of this grunt work for me.
Well, now it does! To ease things a bit, you could certainly wrap the T/SQL required for the manual approach into a stored procedure. This had the benefit of making sure the cascading actions were applied consistently (you no longer had to worry about a developer forgetting to include the necessary logic and corrupting the database), but it was often hard to ensure that your stored procedure was generic enough to address all the scenarios your application might require. The obvious solution would seem to be triggers. They allow you to automatically take some action every time the base table changes. The problem with using triggers, however, is that SQL Server enforces table constraints before firing triggers. As a result, if you wrote a trigger like the one in Listing 1 on a table that was the master (referenced) table of a foreign key relationship hoping that it would delete all the child records, the trigger would not work. Instead, SQL Server would return an error indicating that the "DELETE statement conflicted with COLUMN REFERENCE constraint," so the trigger would never fire. Listing 1: Problem Trigger The way around this, of course, was to drop the foreign
key constraints on your tables and manage all the referential integrity in
triggers. Simple triggers like the one above quickly grew into multi-page
maintenance nightmares. What a drag!
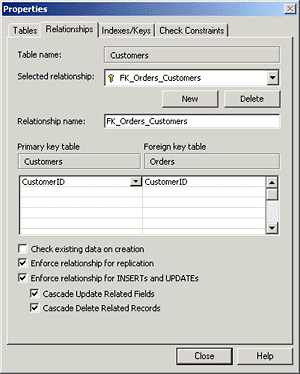
This is all fixed in SQL Server 2000. Now, with just two
clicks of the mouse from the table properties dialog, as shown in Figure
1, you can have SQL Server take care of synchronizing your master and
child tables.
Once you have enabled cascading updates and deletes, when
you delete a customer, SQL Server will automatically remove all the orders
associated with that customer. No fuss, no muss.
Beside the obvious benefit of reducing the tedious code we
developers need to write and enabling us to focus our time and energy on
more interesting tasks, cascading updates and deletes has the added
benefit of increasing the performance of our applications. Remember, all
that T/SQL we built into the triggers had to be parsed, optimized, and
executed at run time. Now, these cascading actions are built into the
table definitions and occur inside the SQL Server engine.
For a very interesting discussion of the interaction among
constraints, cascading actions, and the SQL Server 2000 system tables, see
Chapter 6 of Inside Microsoft SQL Server 2000 (0-7356-0998-5).
When Microsoft first announced that SQL Server 2000 would
finally include cascading referential integrity, I commented that this
would be the end of triggers; I called it the trigger-be-gone feature. It
turns out I was wrong. While it will be the end of triggers as we
currently use them, we will now start to use triggers in a completely
different manner, because the SQL Server 2000 development team added two
new types of triggers to our arsenal of development tools.
Trigger
Enhancements Unlike triggers in SQL Server 7.0 and the AFTER triggers
in SQL Server 2000, an object can only have a single INSTEAD OF trigger.
Another important difference is that an INSTEAD OF trigger fires instead
of the triggering event. In other words, only the trigger executes; the
original statement does not. INSTEAD OF triggers have two main
uses:
Let's look at examples of these two cases, starting off
with adding new rows to a view. Listing 2: Creating the Sample
Tables CREATE TABLE tblLocation ( Finally, I created a view in Listing 3 to display the temperature readings in both Celsius and Fahrenheit. Listing 3: View to Display Temperature
Readings CREATE VIEW qryFahrenheit Now, while you can issue INSERT and UPDATE statements against views, doing so is subject to a complex set of rules and one of them is that you the view cannot contain any derived columns in the select list. Therefore, if I want to add rows to my view, I cannot do so directly because the view contains the calculated Fahrenheit column. In earlier versions of SQL Server, this view would have been nonupdateable. To add rows to it, I would have to write directly into the base tables rather than through the view. This complicates my application because I would have to know the layout of the base tables. Sort of defeats the purpose of a view, doesn't it? With SQL Server 2000, you can hide this complexity from your developers by creating and INSTEAD OF trigger like Listing 4: Listing 4: A Sample INSTEAD OF
Trigger CREATE TRIGGER tiiFahrenheit ON qryFahrenheit The first thing you will notice is that we can now create triggers on views. Other than that, it is a normal trigger. We are simply taking the values out of the special INSERTED table and adding them to the base table, tblTemperature. I am able to hide the physical layout of my base tables from the developer. No matter how many tables are included in the view and no matter how complex the relationships, all the developer needs to do is insert a row into the single view. From there, I can distribute the data to any table I like. To add a row to the view, you would use an INSERT statement like this: INSERT INTO qryFahrenheit The potentially confusing thing about this statement is that you must provide values for every column in your view that does not allow null values. In other words, if the column in the base table has NOT NULL as an attribute, you must provide a value in your INSERT statement. This even applies to IDENTITY columns. Luckily, the query processor makes this easy for you so you don't have to deal with SET IDENTITY_INSERT statements. Rather, you can just pass a placeholder value�0 in my example�and SQL Server will take care of the rest. Using INSTEAD OF
Triggers to Correct Constraint Violations As I mentioned in the earlier section on cascading updates and deletes, one of the main drawbacks of traditional triggers is that you cannot use them to recover from constraint violations, because SQL Server's query processor enforces constraints before firing triggers. Therefore, if your statement violates a constraint, your trigger will never fire. INSTEAD OF triggers, on the other hand, fire before SQL Server checks the constraints. Thus, you can write your INSTEAD OF triggers to anticipate constraint violations and attempt to fix them. Continuing with our simple temperature database, let's add primary keys as shown in Listing 5 to both tables and then establish a foreign key relationship between tblLocation and tblTemperature. Listing 5: Adding Primary Keys and a Foreign Key
Relationship ALTER TABLE tblLocation Let's use the same INSERT statement again, but this time let's clear out both tables first: DELETE FROM tblTemperature If you execute this batch as is, it will fail to insert any rows because your INSTEAD OF trigger is trying join the LocationName of "Pacifica" in the special INSERTED table to the empty table tblLocation. Obviously, it will not return any rows. Initially, you may be tempted to give up on inserting data into the view and attempt to write directly into the base Temperature table. This, however, won't work either; if you try, you will receive an error due to the foreign key constraint. To solve this dilemma, you need to alter your INSTEAD OF trigger as shown in Listing 6 to insert any necessary rows into the Location table before attempting to add data to the Fahrenheit view. Listing 6: The Altered INSTEAD OF
Trigger ALTER TRIGGER tiiFahrenheit ON qryFahrenheit -- Insert any new locations INSERT INTO tblLocation (LocationName) -- Insert temperature readings INSERT INTO tblTemperature Now your trigger handles all the logic, allowing your
developers to insert into the Fahrenheit view without having to worry
about the layout of the underlying tables. The next step would be to
create update and delete INSTEAD OF triggers. That is, as they say, an
exercise that will be left to the reader. Unlike INSTEAD OF triggers, you may only create AFTER triggers on tables; you cannot create an AFTER trigger on a view. You would use the following syntax to create a simple AFTER trigger on our tblLocation table to prevent deletions of the Pacifica row. CREATE TRIGGER tdaLocation ON tblLocation Controlling Trigger
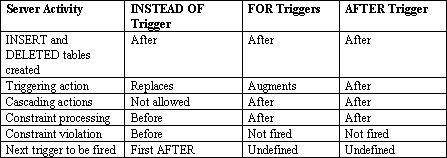
Firing In SQL Server 2000 we are now able to specify which trigger will fire first and which will fire last. Any other triggers (the �middle� ones) will still fire in an indeterminate order. To specify the order, you use the following syntax: sp_settriggerorder @triggername = 'tdaLocation', Here, @triggername specifies the sysname of the trigger, @order is either FIRST or LAST (cannot have the same trigger be both the first and last trigger), and @stmttype is INSERT, UPDATE, or DELETE. The firing order of triggers gets a little complex, so I
have summarized some of the more critical information in Table 1 below.
For simplicity's sake, I will separate FOR and AFTER triggers even though
SQL Server processes them the same way. For a full explanation, see the
SQL Server 2000 Books On Line.
To learn more about triggers in SQL Server 2000 and how
you can design your applications to make the best use of them, see Chapter
9 in Ron and Kalen's Inside Microsoft SQL Server 2000
(0-7356-0998-5). In this article, I have shown you how you can use the new cascading referential integrity and trigger features in SQL Server 2000 to increase the performance of your applications and give you greater flexibility as you design you applications. The new cascading updates and deletes will speed up your applications and release you from the drudgery of writing pages of T/SQL code. You can use the INSTEAD OF trigger to handle constraint violations proactively. Finally, sp_SetTriggerOrder enables you to control the order in which your AFTER triggers will fire. Microsoft Press
Solutions Even if you plan to purchase the SQL Server 2000 version the very day it is published, you should also get a copy Inside Microsoft SQL Server 7.0 if you plan on supporting any 7.0 applications. There are enough differences between the two products to make both texts essential for the serious SQL Server developer. If you simply want to get a quick overview of the new features in SQL Server 2000, take a look at this article on the in the SQL Server section of Microsoft.com: What's New in SQL Server 2000. If you are after a comprehensive look at the new features along with lots of sample code, check out Carl Nolan's excellent MSDN article SQL Server 2000: New Features Provide Unmatched Ease of Use and Scalability to Admins and Users. Other titles from Microsoft Press you might want to check out include the following.
You'll find a complete list of all Microsoft Press SQL Server 2000 resources on Microsoft Press Online. For detailed information on all Microsoft Press's Windows 2000 titles for developers, visit the Windows 2000 for Developers page. For a complete list of all the developer titles, see the Developer Tools section. |